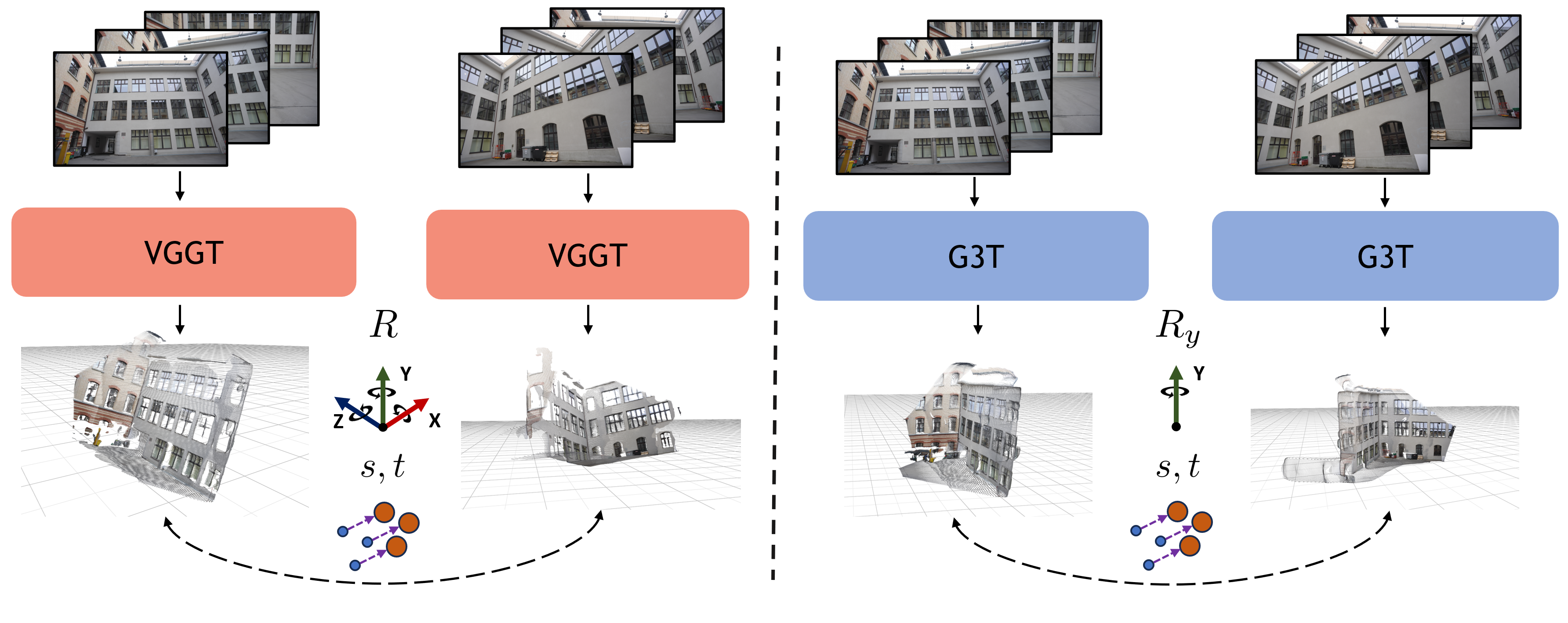
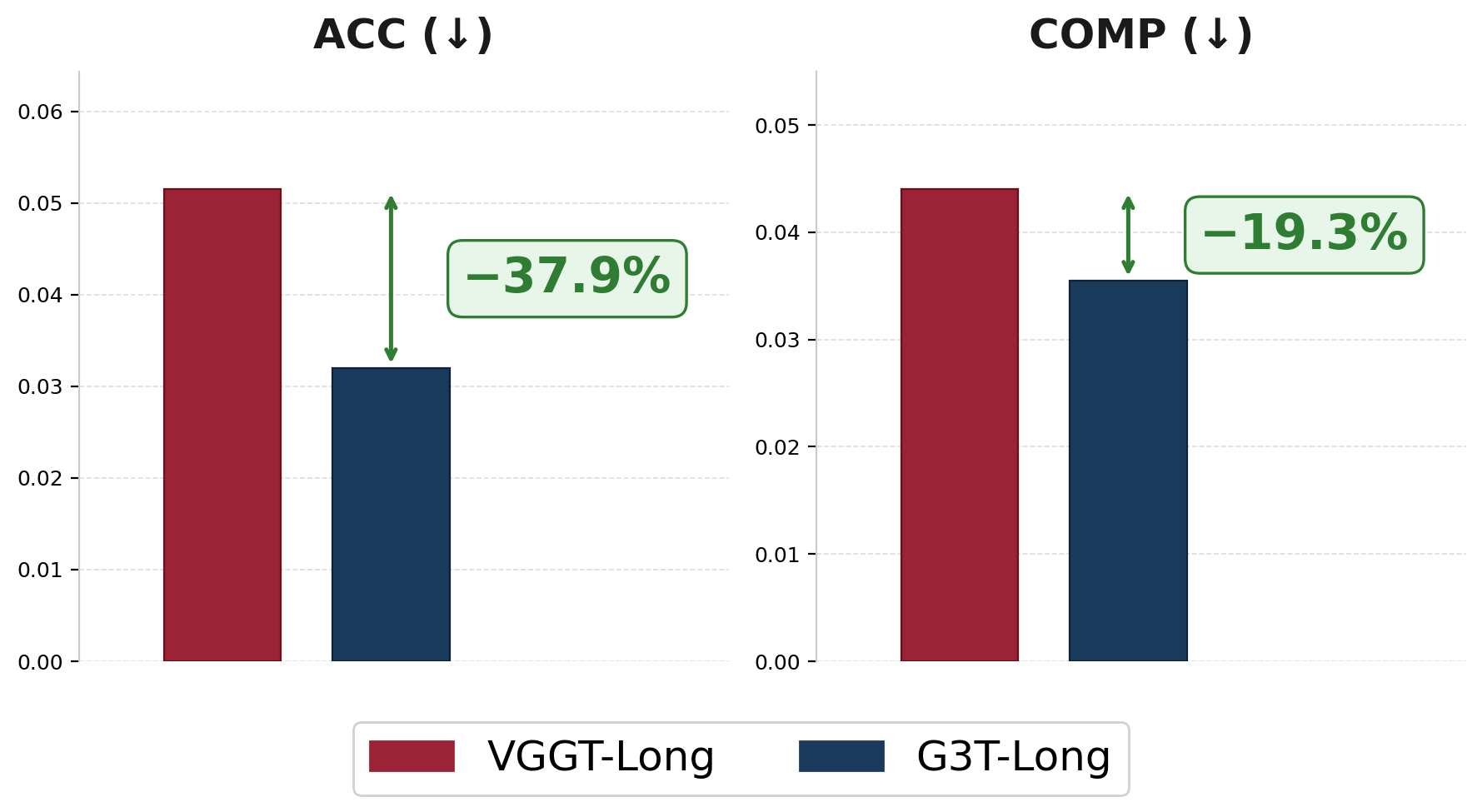
Model Architecture
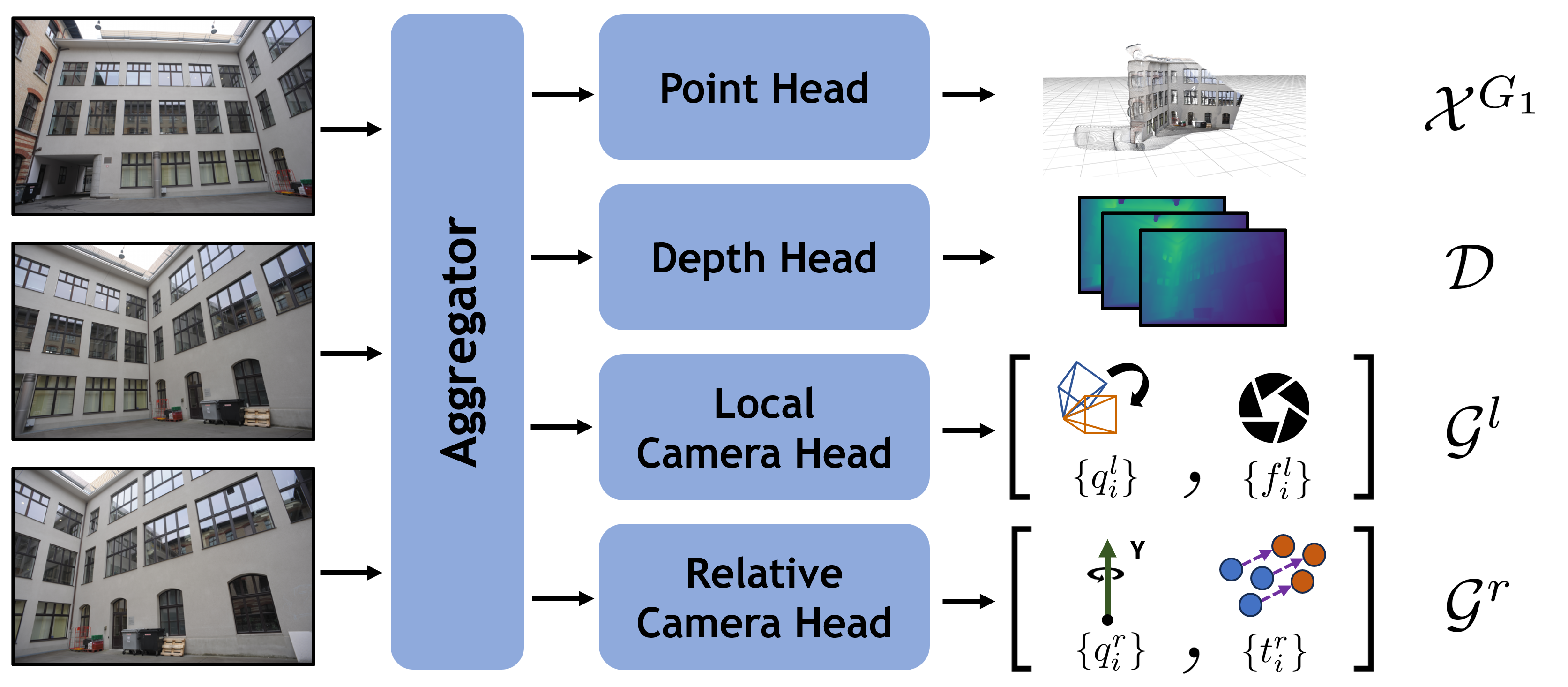
G3T builds upon VGGT with two key modifications. First, the point head outputs pointmaps in the gravity-aligned frame of the first image (\(\mathcal{X}^{G_1} = \{X^{G_1}_i\}\)). Second, we replace VGGT's camera head with two new heads: the local camera head, whose outputs capture gravity-to-camera rotation and camera intrinsics parameters in \(\mathcal{G}^l = \{G^l_i\}\); and the relative camera head, which capture 1-DoF relative yaw and translation parameters in \(\mathcal{G}^r = \{G^r_i\}\). The aggregator, depth head, and point head architectures are otherwise unchanged from VGGT.